
Hash Indexes, for adventurers
Chronicles of DB Indexes - Part 12

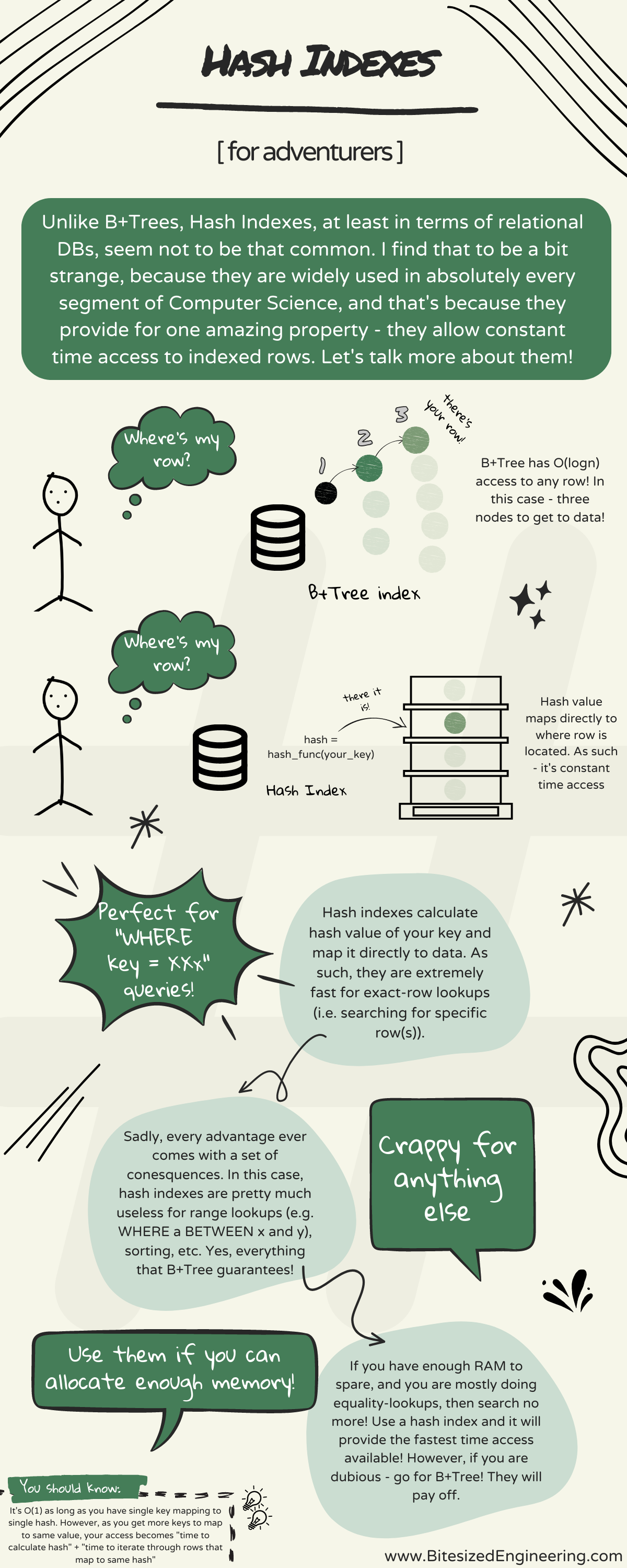
Wrapping up the series on Indexes with graphic on Hash Indexes themself.
So far you probably learned that Hash Functions serve one amazing purpose - they map from infinitely large (or small) universe of elements to a limited and fixed-sized one :) Or, in simple terms - no matter the length of input, they always produce same-sized output.
This makes them perfect for plethora of use-cases, but one of them is O(1) lookups in Relational DBs!
I'm going to greatly simplify things, but - SQL Server uses the term "buckets" and says that Hash Indexes map your keys to predefined buckets. But what does that mean? Well, picture this - let's assume that you get bunch of CVs and you want to store them somewhere for quick retrieval. But not just "fast", but you want to guarantee that time that it takes you to find ANY CV (by it's first name), will ALWAYS be the same.
B+Tree sadly won't help, because it basically grows with your data (and it does so because it preserves original data in it). But, if you were to have, say, 10 folders, and you could quickly find out in WHICH folder your CV is, you'd have almost-constant time access (i.e. you do two steps - calculate folder number and then you open it and take the CV out). Well, those 10 folders are what SQL Server calls - buckets. Number of predefined buckets in which your data could end up in. And a function that tells you WHERE to put or look for specific CV is, believe it or not, a HASH function :)
So what SQL Server does is - it takes your key, calculates the hash value (e.g. something like HASH(first_name) % 10) and based on the output - knows EXACTLY where to look for your data.
One might wonder - but didn't you say that loading Pages from disk is slow and yadda yadda yadda? I did. And that still holds. And that's why Hash Indexes are available only in Memory-optimized tables (called "Hekaton" - a Greek word for "a hundred" - idea being that it should be 100 times faster than regular on-disk table).
Hash indexes are supported for tables that exist in memory only. And since memory access is quite fast - hash indexes give you the best bang for your buck!
But there are downsides as well. And the downside is - exact-row lookup (i.e. WHERE a = XXX) is basically the only thing you can do with Hash Indexes. You can't even do negation (e.g. WHERE a != XXX) because there's just no way to select everything that DOES NOT match specific hash :) That's why anything other than exact-row lookup will end up with table-scan (i.e. it scans all your data). Additionally, ranges are not supported either.
To wrap it up, valid question becomes - when to use Hash Indexes? And I'd say -- only if you are sure you'll need exact-key lookups all the time. For anything else, you're likely way better of with B+Trees :)
P.S. I’m going to put a break on DB series and will focus on Containers and Containerization for a while. This is primarily because I developed incredible interest in how Containers work under the hood (especially on Windows!). Let’s see how that works out!
Until then!