
B+Trees vs B-Trees
Chronicles of DB Indexes - Part 7

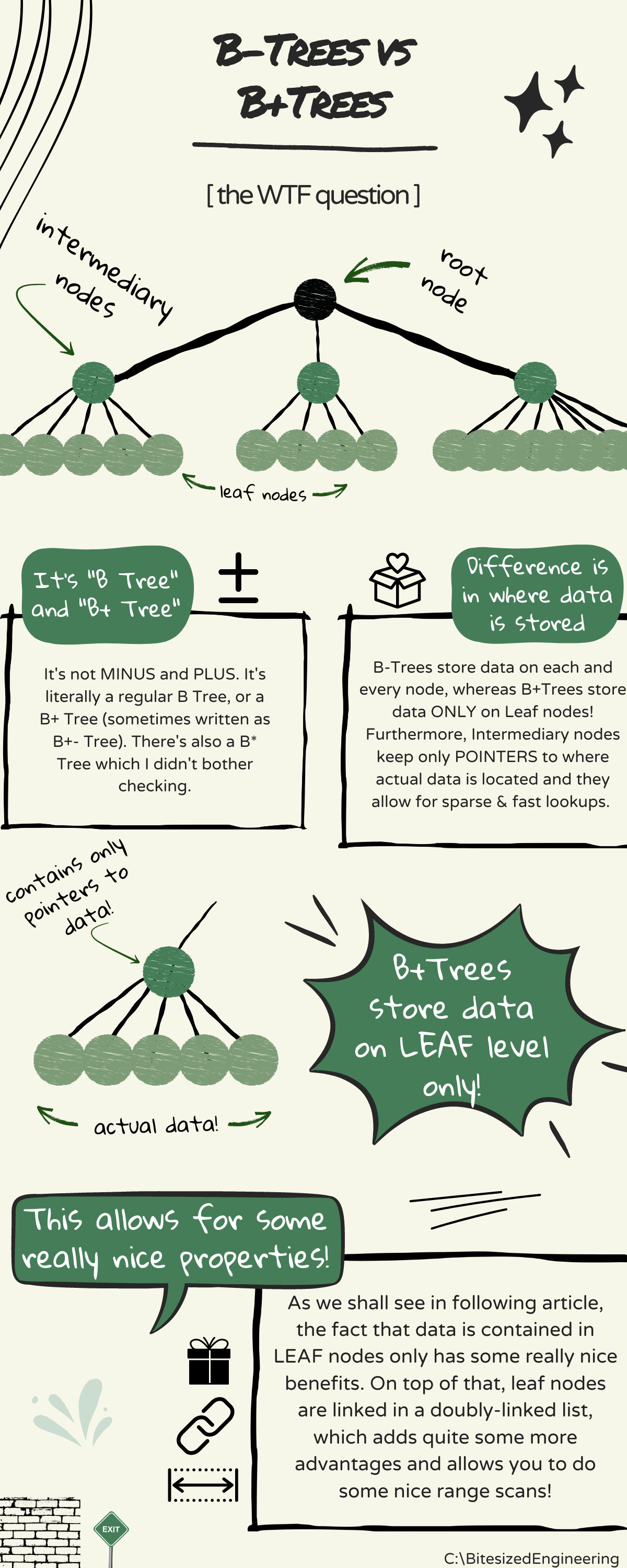
Time to talk about B+Trees :)
I mentioned before that people would usually refer to B-Trees, but what they usually mean is "B+Trees". They are the same but there are some differences that make B+Trees more suitable for indexing data (in DBs, File Systems, etc.).
If I were to pick two most important characteristics of B+Trees, those would be:
- They store data on leaf level only, and
- Leafs are linked in a singly linked list
Both characteristics are quite important as they allow for plethora of optimizitaions when accessing your data. And yes, I'm trying to explain those while still avoiding the overload with index topic. It's a battle!
Let me first focus on the first one. Be it a primary or secondary index, intermediary nodes NEVER contain actual data! Instead, all they have is a POINTER to leaf node where actual data is stored. If you go and explore the topic further (which I highly recommend you do), you would learn that there are TWO types of indexes - Sparse & Dense. Former one is used when you want to provide kind of probabilistic reference that a range of data exists somewhere, whereas dense ones are used to store actual data.
As you could have guessed - Intermediary nodes are sparse, while Leafs are dense.
Another advantage of this approach (which I'll explain more in-depth with next post) is the fact that this reduces amount of hops you need to reach the leaf! What's more, I read some stats that even DBs with terabytes of data have no more than 2-3 levels of intermediary nodes! Just think about this for a moment. Even with TERABYTES of data, all you'd need are four page jumps to reach your data! FOUR! Compare that to Binary Tree where it'd take you like 100-1000 hops to reach the destination.
Finally, a fact that your leafs are linked in a list allow for something called Range Scan. Or, to be more precise - it allows you to load range of data in a SINGLE go!
Pause & ponder this for a sec again. If there were no direct link between leaf nodes, you'd have to be jumping back & forth to load data that is spanned over multiple leaves (anyone who ever had to traverse a tree would tell you this is pain in the ass). However, given the fact that each leaf points to the next one - you can simply jump to another leaf and another and another, effectively making data collection a linear (and blazing fast) process!
Some people would call this a RANGE scan (e.g. SELECT name FROM customer WHERE id BETWEEN 10 an 10000) but all it really is is - engine finding first leaf of a range and then just following pointers until it gets to the last one. SUPER-FAST :)
Anyway, in order to save some specifics for next article, I'll pause here.
Please do think about this and let me know if you want me going more in-depth or if anything is unclear!
Until then!