
A bit on HDD fragmentation
Chronicles of DB Indexes - Part 5

Previous article discussed how HDDs work (not SSDs but HDDs!), and in this one I want to dig a bit deeper into what HDD does with your data. All of this with the ultimate goal of showing you how your data ends up being stored, what it takes to load it and, eventually, why B-Trees ended up being invented.
I'm sure there are those of you old enough to remember Disk Defragmenter, right? It kind of lost it's purpose when SSDs came but it was a really fun experience to watch and wait for :)
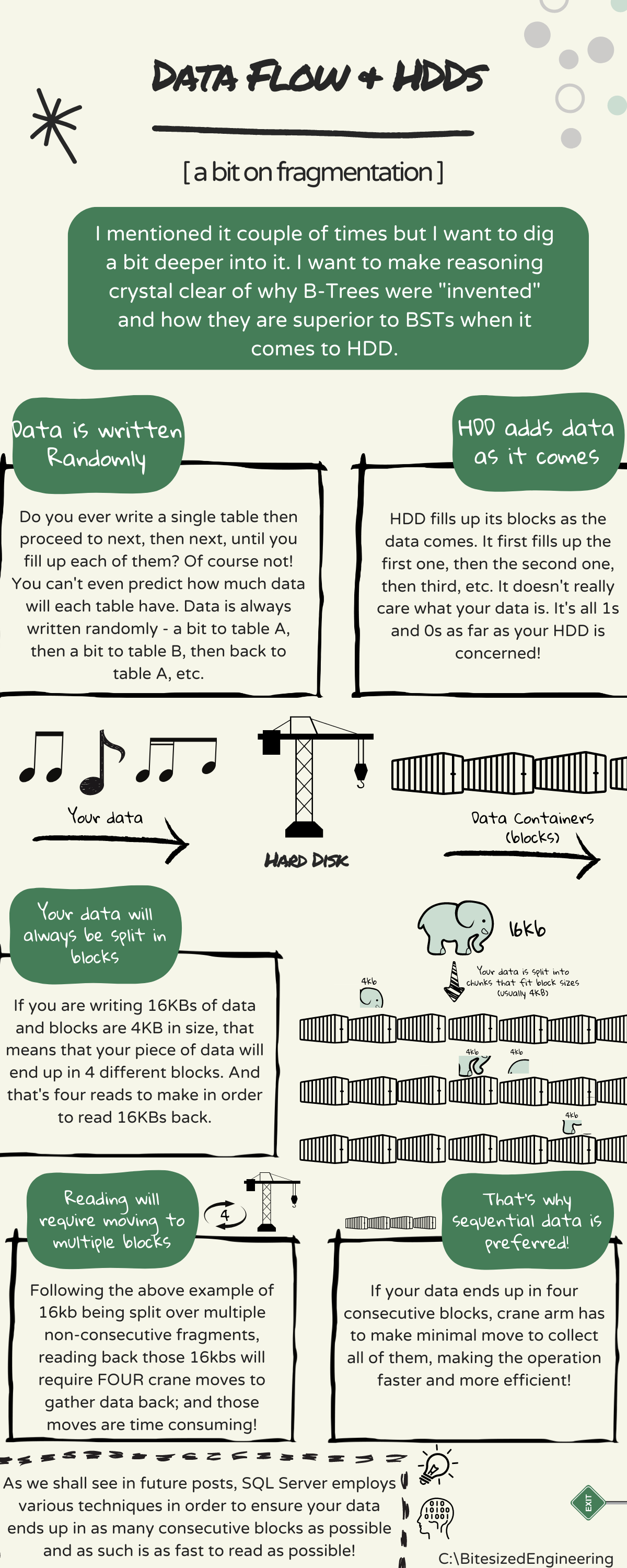
Here is the main thing about all data that was, is, and ever will be stored on a permanent storage - it comes RANDOMLY! Some might argue this from philosophical point of view, claiming that nothing in nature is random and everything is predetermined but that's something I'd pass on for now. Data is RANDOM ENOUGH for the case I'm making here.
If you think solely about a database and your application using it, what you do is you store data to different tables based on output of some action (user interaction, background process, etc.). Assuming that those processes are random enough (i.e. you are ot running a single thing storing a single chain of data, usually called a ledger), what you are effectively doing is storing data in random order (i.e. a bit to Table A, then a bit to Table B, etc.).
All would be good if you just kept ADDING data (which, by the way is what transaction log and blockchain do!). But the problem is that you are MODIFYING as well - editing, deleting, copying, etc. You are effectively constantly moving your data from one disk block (container) to another. And this leads to - fragmentation! Because if you were to fill 10 blocks with data, then removed something from blocks number 3, 4 and 5 - HDD would reuse those blocks to store part of data, while storing other parts to other containers. And this is what fragmentation is - you take a big chunk, split it into container-sized pieces and store them in any container that has data.
Eventually you end up with your data being split all over the place. Your 16.000 zeros and ones (16kb) might end up in 10 different containers and crane has to do A LOT of job to pick them up.
This fragmentation is EXACTLY what problem is with BSTs - they contain too few data (max 2 children per node!) and they end up being fragmented all over the place! This is fine when you have fast-access memory (e.g. RAM), but pain in the ass when you have mechanical movement process in the background.
And that, folks, is why B-Trees were made! Made to pack AS MUCH DATA AS POSSIBLE, so that when fragmentation occurs, at least you have bulk of your data in a single container! And that's what we will discuss in the next article :)
Stay tuned!